Small Language Models: The Rise of Efficient AI
How small language models (SLMs) like Phi-4 and Mistral are challenging large language models with efficiency, speed, and specialized capabilities.
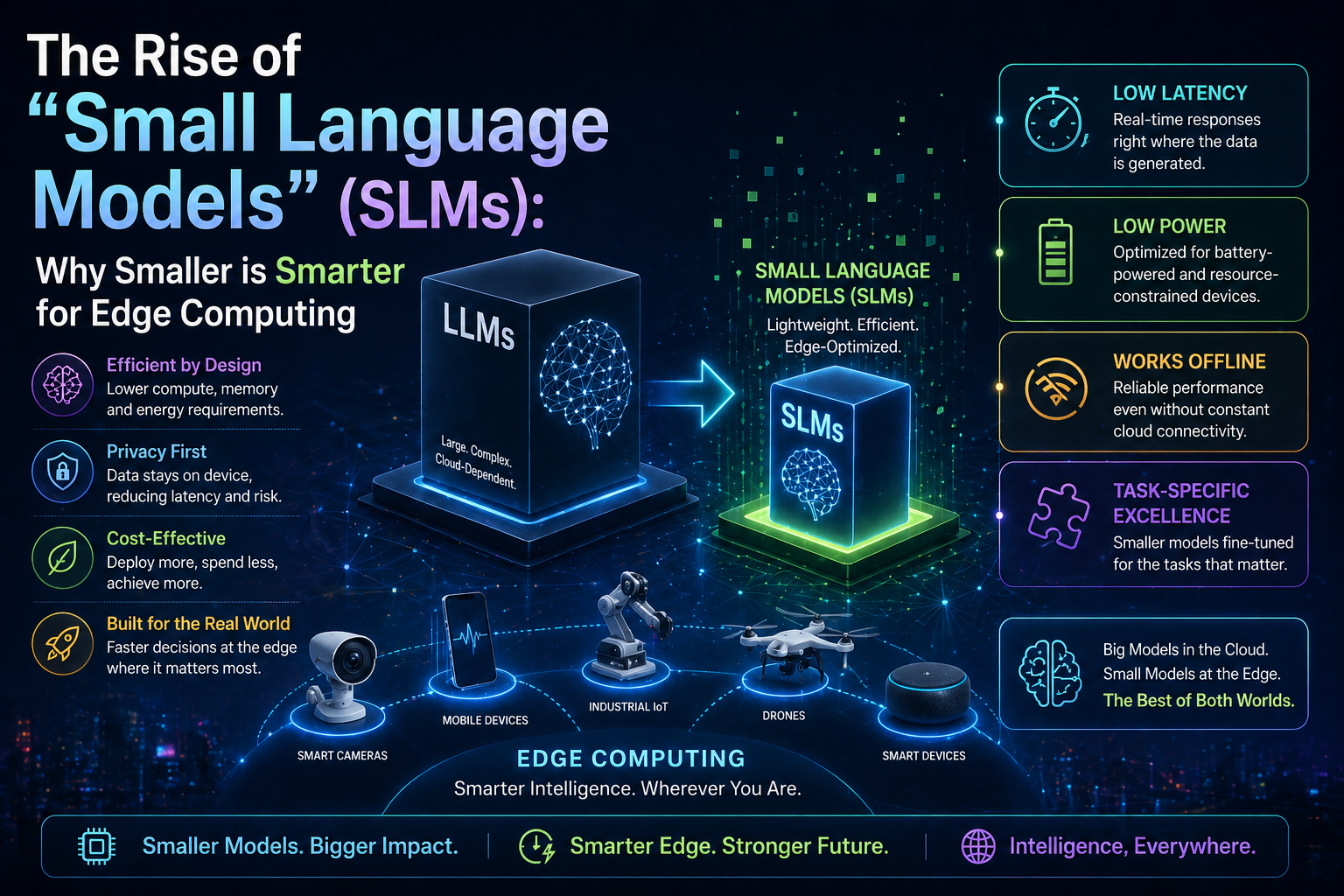
The AI industry has been obsessed with larger models for years — GPT-4, Claude, Gemini, each bigger than the last. But a counter-movement is gaining momentum. Small language models (SLMs) like Microsoft's Phi-4, Mistral's family of models, and Google's Gemma are proving that bigger isn't always better. These compact models offer significant advantages: faster inference, lower costs, easier deployment on edge devices, and often comparable — or even superior — performance on specific tasks. This article explores the rise of small language models, their architecture innovations, use cases, and how they complement their larger counterparts in the AI ecosystem.
Introduction
For most of 2023 and 2024, the AI industry was defined by a simple metric: parameter count. Teams raced to build larger models, with some exceeding a trillion parameters. The assumption was straightforward — more parameters meant more capabilities, more knowledge, and better performance.
But the economics of scale were catching up. API costs remained high, latency frustrated users, and deploying large models required expensive infrastructure. Meanwhile, a quiet revolution was happening at Microsoft, Mistral, and Google. Their small language models were achieving remarkable results with a fraction of the parameters.
The numbers tell a compelling story. Phi-4, Microsoft's latest small model, operates with just 14 billion parameters but matches or exceeds larger models on many benchmarks. Mistral's models consistently outperform models twice their size. The efficiency gap is closing fast.
What Are Small Language Models?
Defining the SLM Category
Small language models typically contain between 1 billion and 15 billion parameters — a fraction of the 100+ billion parameters in models like GPT-4. Despite their compact size, SLMs leverage several key innovations:
Quality over Quantity in Training Data: SLMs are often trained on carefully curated, high-quality datasets rather than the entire internet. This "distilled" knowledge approach yields more focused capabilities.
Advanced Architecture: Techniques like mixture of experts (MoE), knowledge distillation, and efficient attention mechanisms maximize performance within smaller parameter budgets.
Specialization: Many SLMs are optimized for specific domains or tasks rather than general-purpose capabilities.
The Parameter Efficiency Revolution
The table below highlights how SLMs achieve comparable performance with significantly fewer parameters:
| Model | Parameters | Context Length | Strengths |
|---|---|---|---|
| Phi-4 | 14B | 128K | Reasoning, coding |
| Mistral 7B | 7B | 32K | General purpose, speed |
| Gemma 2B | 2B | 8K | Edge deployment |
| Qwen 1.8B | 1.8B | 32K | Multilingual |
Why SLMs Matter Now
The Cost Equation
API costs for large language models remain substantial. Running GPT-4 at scale costs pennies per thousand tokens, but at enterprise volumes, these pennies become millions. SLMs reduce these costs by 10x to 100x while delivering 80-90% of the capability for many use cases.
Latency Benefits
For real-time applications — customer service chatbots, coding assistants, interactive tools — latency is critical. SLMs can generate responses in milliseconds compared to seconds for larger models. This speed difference transforms what's possible.
Deployment Flexibility
Large models require data center GPUs. SLMs run on consumer hardware, edge devices, mobile phones, and even browsers. This opens use cases impossible with larger models: offline AI, privacy-sensitive applications, and instant responses without network calls.
Use Cases Where SLMs Excel
Code Completion and Software Development
SLMs like Phi-4 excel at code completion, bug detection, and feature generation. Their focused training on code repositories makes them surprisingly capable for their size.
Domain-Specific Intelligence
Organizations can fine-tune SLMs on their proprietary data — internal documentation, product specifications, support tickets — creating specialized assistants without the overhead of large models.
Edge and Embedded AI
IoT devices, robots, and embedded systems benefit from SLMs that run locally without cloud connectivity. This enables new categories of intelligent hardware.
Rapid Prototyping
For teams building AI applications, SLMs offer fast iteration cycles. Testing ideas with small models before investing in large model APIs accelerates development.
The SLM vs LLM Complementarity
When to Use Each
Small and large models serve different purposes. Understanding when to use each is key:
| Use Case | Best Model | Reason |
|---|---|---|
| Real-time chat | SLM | Speed, low latency |
| Complex reasoning | LLM | Broader knowledge |
| Code generation | SLM or LLM | Depends on complexity |
| Creative writing | LLM | Quality, variety |
| High-volume tasks | SLM | Cost efficiency |
| Research analysis | LLM | Depth, accuracy |
The Hybrid Approach
Many production systems use both. Simple queries route to SLMs for fast, cheap responses. Complex queries escalate to LLMs for deeper processing. This tiered architecture optimizes both cost and quality.
Leading SLM Implementations
Microsoft Phi Series
Microsoft's Phi series has defined the SLM category. Phi-4 demonstrates that thoughtful training data selection — "textbook quality" data — matters more than raw quantity. The model's reasoning capabilities rival models twice its size.
Mistral AI
Mistral's open-source models have built a passionate developer community. Their mixture-of-experts architecture routes queries to specialized "experts" within the model, achieving efficiency without sacrificing capability.
Google Gemma
Google's Gemma family targets edge deployment. Gemma 2B runs on consumer GPUs, making AI accessible for local applications.
Alibaba Qwen
Qwen's multilingual capabilities make it valuable for global applications. The model's performance across languages — including English, Chinese, and code — exceeds expectations for its size.
Challenges and Limitations
Knowledge Boundaries
SLMs simply know less — their training data capacity is smaller. They may struggle with obscure topics or highly specialized domains requiring deep expertise.
Hallucination Risks
Like all language models, SLMs can generate incorrect information. Smaller models may hallucinate more frequently when operating outside their training distribution.
Context Windows
Many SLMs have shorter context windows than large models. This limits their effectiveness for analyzing long documents or maintaining extended conversations.
The Future of SLMs
Trends to Watch
The SLM category is evolving rapidly. Expect:
- Longer Context Windows: Next-generation SLMs will support 100K+ tokens
- Better Specialization: More fine-tuned variants for specific industries
- Multimodal Capabilities: Vision and audio processing in small packages
- On-Device AI: Full AI assistants running on smartphones
Market Impact
SLMs won't replace LLMs, but they will capture significant market share. Estimates suggest SLMs will handle 40-50% of current LLM use cases by 2028, driven by economics and deployment flexibility.
Conclusion
Small language models represent a fundamental shift in how we think about AI capabilities. The obsession with parameter count is giving way to efficiency thinking. For many real-world applications, smaller is actually better — faster, cheaper, and more accessible.
The AI industry is discovering that there's room for both giant and nimble models. SLMs aren't replacing LLMs; they're expanding what's possible. From edge devices to cost-sensitive enterprises, the rise of efficient AI is democratizing access to artificial intelligence capabilities previously reserved for those with massive infrastructure budgets.
The future of AI isn't just bigger — it's smarter about when size matters and when it doesn't.
Related Articles

Multimodal AI Benchmarking: Comparing Vision-Language Models
A comprehensive comparison of leading multimodal AI models — understanding their capabilities, limitations, and ideal use cases.

The Open-Source AI Revolution: How DeepSeek, Qwen, and Open Models Are Reshaping the AI Landscape
Open-source AI models like DeepSeek and Qwen are challenging proprietary giants, with Google's Vertex AI now listing Chinese models alongside OpenAI offerings in a remarkable shift.

Large Language Models: Understanding Modern AI's Most Transformative Technology
A comprehensive guide to large language models (LLMs), their architecture, capabilities, applications, and implications for the future.